Pipeline
Una pipeline è una serie di processi, solitamente lineari, che filtrano o trasformano i dati (ETL).
Si presuppone generalmente che i processi vengano eseguiti contemporaneamente. Il diagramma del flusso di dati di una pipeline normalmente non si ramifica né si ripete.
Il primo processo prende i dati grezzi come input, fa qualcosa su di essi, quindi invia i risultati al secondo processo e così via, per finire infine con il risultato finale prodotto dall'ultimo processo nella pipeline.
Le pipeline sono normalmente veloci, con un flusso che impiega da secondi a ore per l'elaborazione end-to-end di un singolo set di dati.
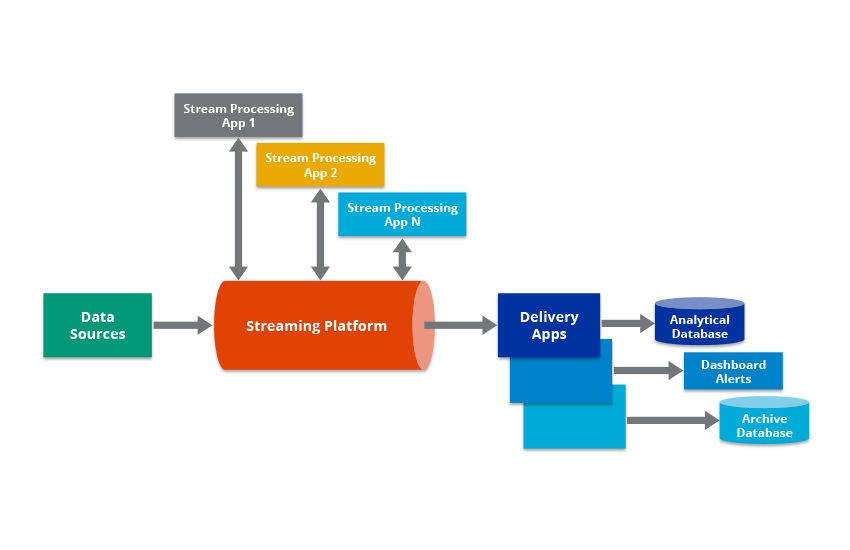
Cos'è una pipeline di dati ?
Definizione della pipeline di dati
Una pipeline di dati è la serie di passaggi consecutivi automatizzati di elaborazione dei dati coinvolti nell'acquisizione e nello spostamento di dati grezzi da fonti disparate a una destinazione.
Quindi, una pipeline di dati è un processo sistematico e automatizzato per lo spostamento, la trasformazione e la gestione efficiente e affidabile dei dati da un punto a un altro all'interno di un ambiente informatico.
Svolge un ruolo cruciale nelle moderne organizzazioni basate sui dati consentendo il flusso continuo di informazioni attraverso le varie fasi dell'elaborazione dei dati.
Una pipeline di dati è costituita da una serie di passaggi di elaborazione dei dati.
Se i dati non sono attualmente caricati nella piattaforma dati, verranno inseriti all'inizio della pipeline.
Poi ci sono una serie di passaggi in cui ogni passaggio fornisce un output che costituisce l'input per il passaggio successivo.
Ciò continua fino al completamento della pipeline.
In alcuni casi, è possibile eseguire passaggi indipendenti in parallelo.
Pipeline & ETL
C'è spesso confusione tra pipeline ed ETL.
ETL comprende 3 passaggi principali.
Extract - Estrazione: acquisizione/acquisizione di dati da sistemi di origine originali e disparati.
Transform -Trasforma: spostamento dei dati in un archivio temporaneo noto come area di staging. Trasformare i dati per garantire che soddisfino i formati concordati per ulteriori usi, come l'analisi.
Load - Carica: caricamento dei dati riformattati nella destinazione di archiviazione finale.
Questo è un approccio comune ma non l'unico allo spostamento dei dati.
Infatti, non tutte le pipeline hanno una fase di trasformazione.
Quindi non sempre in una pipleine esiste l' ETL.
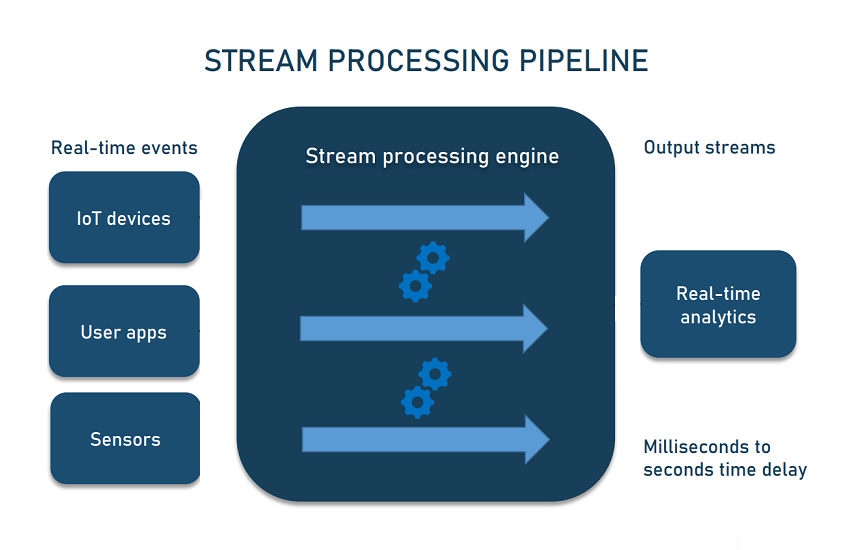
Conclusione
Quindi una pipeline di dati automatizza lo spostamento e la trasformazione dei dati tra un sistema di origine e un repository di destinazione utilizzando vari strumenti e processi relativi ai dati.
Per comprendere il funzionamento di una pipeline di dati, si può considerare uno stadio in cui si riceve un input da una sorgente che viene trasportata per fornire output a destinazione.
Una pipeline può includere una attività di filtro e selezione di dati, la normalizzazione e il consolidamento dei dati per fornire i dati desiderati.
Può anche consistere in processi semplici o avanzati come ETL (Extract, Transform and Load) o gestire set di dati di addestramento in applicazioni di machine learning.
Workflow
Il workflow è un insieme di processi, solitamente non lineari, che filtrano o trasformano i dati, spesso innescando eventi esterni.
Non si presuppone che i processi vengano eseguiti contemporaneamente.